Intro
Fn es una plataforma cloud FaaS (Funtions-as-a-Service) de código abierto. Está basada en eventos y puede correr en cualquier nube (cloud agnostic serverless platform).
Entre otras, algunas características principales de éste proyecto son:
- Código abierto
- Docker native
- Múltiples lenguajes de programación
- Agnóstica a la nube (corre en cualquier nube)
- De fácil uso (principalmente para desarrolladores y operadores)
- Está escrita en Go
Instalación
Los pre-requisitos son simples:
- Tener instalado y corriendo Docker 17.10.0-ce o superior
- Tener una cuenta de Docker Hub
- Hacer login en la cuenta de Docker Hub
Instalar la línea de comandos de Fn (CLI)
Esto no es requerido, pero a nadie le cae mal una ayuda. Nos va a facilitar algunas cosas.
Estoy usando Linux, hay maneras de hacerlo en Windows y MacOS. Aquí vamos a mostrar cómo se hace en Linux.
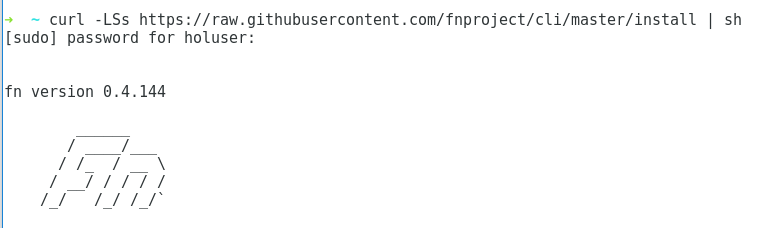
Debemos descargar un shell y ejecutarlo. En caso de estar usando root, todo será transparente. En caso de estar utilizando algún otro usuario, nos va a pedir el password para invocar sudo.
curl -LSs https://raw.githubusercontent.com/fnproject/cli/master/install | sh
Al finalizar la descarga e instalación, veremos lo siguiente en la línea de comandos. En este punto la herramienta de CLI estará instalada:
Podemos verificar que la instalación de CLI fue correcta ejecutando el comando: fn help

Ejecución del Fn Server
El siguiente paso es descargar el binario de Fn. Aquí van a encontrar las versiones disponibles, deberán descargar el que corresponde a su sistema operativo (en mi caso, Linux):
Una vez descargados los binarios, podemos ejecutar el comando para iniciar el fn server: fn start
Como era de esperarse, mi versión de docker era muy vieja. Entonces el primer intento no funcionó.

Pero no se agüiten. Sólo es necesario remover el docker-engine actual e instalar la versión más nueva y chévere de docker-ce (hay que agregar el repositorio correspondiente para poder instalar docker-ce).
Desinstalar docker-engine
sudo yum remove docker

Agregar repositorio de docker-ce e instalar la última versión
sudo yum -y install yum-utils
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
sudo yum -y install docker-ce

Verificar la instalación de docker-ce
docker version

Podemos ver un mensaje que nos indica que el Docker daemon no está iniciado. Como acabamos de instalar docker-ce, debemos iniciar manualmente el demonio y verificar nuevamente. Para poder iniciar el demonio con systemctl, nos va a solicitar el password de sudo:
systemctl start docker
docker version

Segundo intento, levantar el fn server
fn start

Primera función
fn init
Para escribir nuestra primera función, vamos a usar la herramienta CLI que instalamos al inicio. Esto va a permitir crear la primera versión de manera muy simple. Lo unico que debemos hacer es escribir: fn init --runtime go hello
Lo anterior, automáticamente va a generar una carpeta llamada hello y debajo de ella cuatro archivos correspondientes al código de nuestra función:

func.go
El archivo func.go contiene el código de la función. Es un simple hello world. Básicamente la función recibe un parámetro (name). En caso de que el parámetro esté vacío, devuelve "Hello World". En caso de que el parámetro contenga un valor, devuelve un saludo personalizado "Hello Leo".

func.yaml
El archivo func.yaml es llamado func file y es usado para la creación de las funciones de fn project. Lo que definimos en el archivo es: el nombre de la función, la versión de la función, el lenguaje de programación en tiempo de ejecución y el formato de los mensajes.

Gopkg.toml
El archivo Gopkg.toml es un archivo de configuración donde se definen las dependencias de la función.

test.json
El archivo test.json es un archivo utilizado para realizar pruebas de ejecución de la funcion, define entradas y salidas de la función. Esto nos ayudará a saber si la función está operando correctamente o no.

Ejecutar la función localmente
Una vez que está listo el código, vamos a ejecutarlo y a desplegarlo al Fn server local. Para el despliegue vamos a utilizar nuestro usuario de Docker Hub que comentamos al inicio, en los pre-requisitos del post. Vamos a hacer un export a la variable de ambiente FN_REGISTRY, con el usuario de Docker Hub. Una vez hecho esto, vamos a ejecutar la función localmente: fn run
Desplegar la función al Fn server local
Para desplegar la función a nuestro Fn server local, vamos a utilizar el comando: fn deploy --app myapp --local

Probar la función
Para poder probar la función en nuestro Fn server local, vamos a ejecutar alguna de las siguientes opciones:
- Probar en el navegador: http://localhost:8080/r/myapp/hello
- Probar usando curl: curl http://localhost:8080/r/myapp/hello
- Probar usando CLI: fn call myapp /hello
Navegador (usando Firefox):

CURL:

CLI:

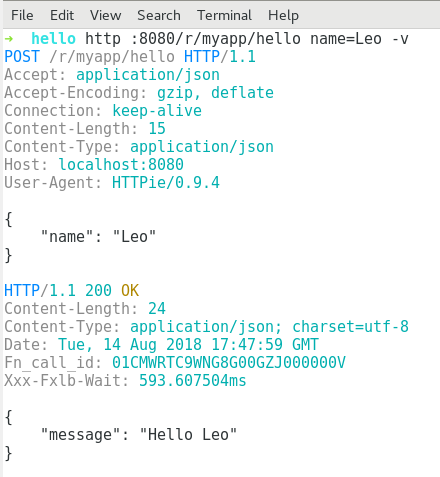
HTTPie
Adicionalmente hice un par de pruebas usando HTTPie. Es una herramienta en modo línea de comandos que nos sirve para enviar requests a un endpoint usando los distintos métodos de HTTP. Esto me va a permitir ejecutar tanto un GET como un POST en el mismo endpoint y poder pasar el nombre a la función sin tener que armar a mano el JSON del payload.
HTTPie (GET):

HTTPie (POST):