La versión particular que estoy utilizando es 12.2.1.0.0; sin embargo, esto se encuentra disponible en 12.1.3.0.0 y 12.2.1.2.0. Así que pueden usar cualquier release de Oracle SOA Suite 12c.
Pre-requisitos
Hay algunas tareas previas que debemos ejecutar para tener en nuestro repositorio local de Maven los elementos necesarios para desplegar aplicaciones de Oracle SOA Suite. Los pre-requisitos son los siguientes:
- Instalar y configurar Maven (por obvio que esto parezca, habrá quien piensa que es magia)
- Configurar Maven para la automatización y configuración de dependencias de proyectos de Oracle SOA Suite 12c. Esto incluye: instalar y configurar el plug-in para la sicronización de Maven, ejecutar el plug-in para la sincronización del Repositorio de Maven, poblar el repositorio de Maven. La documentación oficial de Oracle para realizar esto, la pueden encontrar aquí:
Una vez realizado esto, podemos continuar.
Creación de una aplicación y proyecto de Oracle SOA Suite, utilizando el arquetipo de Maven
Para nuestra comodidad, ya existe un arquetipo que podemos utilizar para crear la estructura inicial de nuestro proyecto. Basta con ejecutar el siguiente comando para crear en nuestro sistema de archivos, la estructura de carpeta de nuestro proyecto:
mvn archetype:generate -DarchetypeGroupId=com.oracle.soa.archetype -DarchetypeArtifactId=oracle-soa-application -DarchetypeVersion=12.2.1-1-0 -DarchetypeRepository=local
El arquetipo usado lo estoy buscando en mi repositorio local, debido a que no existe en el repositorio central de Maven. Es por esto que uno de los pasos previos es poblar el repositorio de Maven siguiendo los pasos de la documentación mencionados arriba.

El resultado de la ejecución, será la creación de las carpetas del proyecto en el sistema de archivos. En mi caso particular voy a crear una aplicación que me sirva para exponer un API para el procesamiento de órdenes de compra que usaré en un futuro para algunas demostraciones. Dentro de esa aplicación, crearé un proyecto para la primer capacidad del API, que me servirá para validar algunos datos del pago, previo al procesamiento de las órdenes de compra.
En la estructura de las carpetas podemos observar lo necesario para crear algunos elementos típicos de un compuesto SOA: Events, Schemas, Transformations, WSDLs, etcétera. Hasta aquí no hemos creado ninguna aplicación (JWS) ni proyecto (PRJ) de JDeveloper. Sólo hemos generado la estructura de nuestras carpetas.

El arquetipo nos crea dos archivos POM: uno de aplicación y otro de proyecto.
Ejecución de comandos de Maven
En este punto podemos empaquetar el proyecto que hemos creado. Esto nos generará un JAR (evidentemente vacío, pues no hemos puesto código dentro del mismo). Para empaquetar el proyecto, ejecutamos el siguiente comando debajo de la carpeta de nuestra aplicación:
mvn package
Si es la primera vez que hacemos esto, vamos a observar un warning como el siguiente. Esto es debido a que la expresión version ya está deprecada; en lugar de esto deberíamos usar project.version.

Corregir lo anterior es muy simple, únicamente debemos abrir el POM que se encuentra debajo del proyecto (generado automáticamente por el arquetipo) y ubicar la expresión en las propiedades de configuración del proyecto.

Entonces reemplazamos version por project.version y guardamos el POM del proyecto. Algo importante es que esto se encuentra en el POM del proyecto, NO en el POM de la aplicación.

Si ejecutamos de nuevo el comando para empaquetar el proyecto, observaremos que el warning ha desaparecido.

El proyecto ha compilado y el paquete se ha generado correctamente.

Para poder validar lo anterior, vamos de nuevo al sistema de archivos generado por el arquetipo. Notamos que se ha creado una carpeta adicional debajo de la carpeta del proyecto. Esta nueva carpeta se llama target. Dentro de ella tendremos el JAR (paquete) generado por Maven.

Import del proyecto en JDeveloper
Dado que el proyecto no tiene código aún, vamos a abrirlo en JDeveloper y agregar algo de funcionalidad. Para realizar esto damos un click en New > Import y veremos un asistente que nos permite importar proyectos de Maven a JDeveloper.

En el directorio raíz, vamos a seleccionar la carpeta donde creamos la aplicación. El archivo de configuración de Maven (settings.xml) se selecciona de manera automática, lo vamos a conservar así.
En la estructura de proyectos debemos elegir tanto el POM de la aplicación, como el POM del proyecto. El resultado de esto es que JDeveloper va a crear el archivo de aplicación (JWS) y el archivo del proyecto (PRJ) debajo de la misma estructura de archivos donde estamos trabajando. En caso de que deseemos colocar el código debajo de otra carpeta (por ejemplo tu propio workspace de JDeveloper), debemos seleccionar la opción: Also import source files into application (no es mi caso, yo quiero trabajar en el mismo directorio).

A continuación, JDeveloper nos pedirá algunos datos adicionales para crear la aplicación. Probablemente les salga una advertencia de sobreescritura del archivo de la aplicación (JWS), debemos aceptar sin miedo (no puede sobreescribirse un archivo que ni siquiera ha sido creado todavía).

Observamos que en nuestra estructura de archivos se ha creado el archivo de la aplicación de JDeveloper (JWS).

También se ha creado el archivo del proyecto (PRJ).

En JDeveloper, ahora podemos ver ambas cosas: aplicación y proyecto.

Implementación del compuesto
Ahora voy a agregar un poco de código al proyecto (aquí pueden implementar lo que ustedes quieran). En el caso de mi ejemplo, agregué lo siguiente:
- Creé un esquema para definir el modelo canónico de mi proceso de negocio.
- Creé un BPEL que realiza la validación de la información un pago.
- Dentro del BPEL coloqué una validación: si el monto de la orden es menor o igual a 1000.00, el pago es aceptado; en caso contrario, el pago es rechazado. Esto a través de XSL.
- Expuse el compuesto en dos interfaces: SOAP y REST (JSON/XML).
Hasta este punto, podríamos compilar y desplegar el código como lo hacemos en forma tradicional, de manera manual.

Parent POM: sar-common
Para poder automatizar las tareas de empaquetado y despliegue del código es necesario utilizar el parent POM: sar-common. Este debería estar previamente instalado en nuestro repositorio local al momento de ejecutar los pre-requisitos.
En el POM de sar-common, debemos hacer algunas modificaciones para la conexión al servidor a donde deseamos desplegar los compuestos. Esto evitará que en cada proyecto debamos de colocar los datos del servidor, así como las credenciales de conexión.
El POM a modificar se encuentra debajo de la siguiente ruta:
.m2\repository\com\oracle\soa\sar-common\12.2.1-1-0
Aquí debemos modificar lo siguiente:
- Usuario y contraseña para la conexión al servidor
- URL del servidor
- Nombre del servidor
- Ruta del Middleware Home

Despliegue desde JDeveloper (usando Maven)
Para la automatización de empaquetado y despliegue del compuesto, vamos a utilizar el goal de Maven llamado: pre-integration-test. Este goal no se encuentra disponible por default en JDeveloper, por lo que debemos agregarlo.
Para agregar este goal damos click derecho sobre el POM del proyecto > Run Maven > Manage Goal Profiles. Esto nos abrirá la siguiente vista:

Click sobre la cruz de color verde > Add Phases > Seleccionar pre-integration-test.

Una vez realizado lo anterior, debemos tener la fase disponible en el menú contextual. Al ejecutar pre-integration-test, el compuesto será desplegado hacia la SOA-INFRA.

Despliegue desde línea de comandos (usando Maven)
Si deseamos desplegar el compuesto desde la línea de comandos, lo primero que debemos hacer es settear la variable de ambiente ORACLE_HOME hacia una instalación válida de JDeveloper. Después ejecutar el siguiente comando:
mvn pre-integration-test
El script de Maven compilará el código.

Posteriormente creará el paquete.

Finalmente realizará el despliegue al servidor.

Validación del compuesto en Enterprise Manager
Una vez desplegado el compuesto, podemos validar el despliegue en Enterprise Manager. Al navegar hacia la vista de compuestos desplegados, podemos observar que el compuesto ya se encuentra en el servidor.

Pruebas del compuesto
A continuación, podemos ejecutar algunas pruebas básicas para validar el funcionamiento del código.
La primer prueba la ejecutamos utilizando un monto total de la orden igual a 100.00. Esto deberá responder Autorizado, de acuerdo a la implementación del XSL.


Ahora ejecutamos una prueba con un monto total de la orden de 2000.00. El pago deberá ser Rechazado.

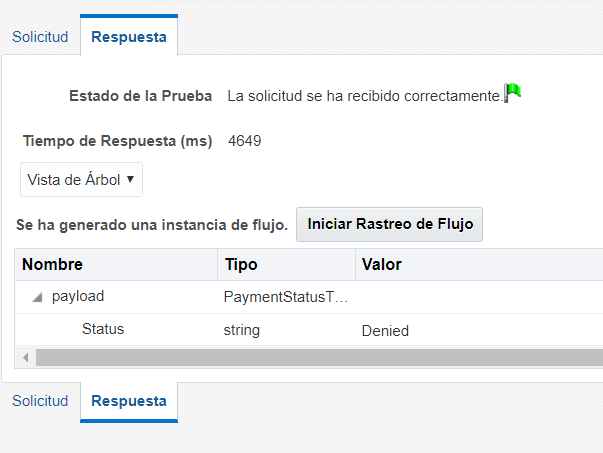
Finalmente, podemos validar que ambas instancias fueron creadas y completadas de manera exitosa.

Algunas conclusiones
- Es posible automatizar tareas de compilación, empaquetado y despliegue de compuestos de Oracle SOA Suite. Este puede ser un primer paso para la implementación de una estrategia de DevOps y Continuous Integration.
- Oracle proveé de un plug-in para configurar y poblar nuestro repositorio local de Maven con los elementos necesarios para tareas de automatización de despliegues.
- A través de Maven (y sus arquetipos) podemos crear la estructura inicial de un proyecto de Oracle SOA Suite.
- JDeveloper nos permite importar proyectos de Maven previamente creados con algún arquetipo.
- Es posible desplegar compuestos de Oracle SOA Suite, de manera automática, desde JDeveloper y desde la línea de comandos.
- El automatizar el despliegue de los proyectos de Oracle SOA Suite, no implica realizar cambios en la forma en que tradicionalmente desarrollamos. Simplemente facilita las tareas del desarrollador al automatizar algunas tareas comunes.
Referencias
En la siguiente referencia pueden encontrar un video que muestra los pasos ejecutados en ésta entrada:






















































